Inleiding
Welkom in de overdrachtshandleiding van H-AI. H-AI is een onderzoeksproject van de Haagse Hogeschool, opgestart in het lesjaar 2024-2025. Het doel van dit project is om te onderzoeken of het mogelijk is, om programmatisch toetsen1 te ondersteunen door quizvragen voor low-stake toetsing te genereren middels generatieve AI.
Deze handleiding is bedoeld ter overdracht van het H-AI project en is opgedeeld in drie onderdelen:
- Context
Hier omschrijven we onder andere de probleemstelling, de opdrachtgever en de projectgroep. - Development
Dit gedeelte is voornamelijk bedoeld voor ontwikkelaars en omschrijft de technische opzet, ontwerpen, keuzes en hoe het project lokaal gedraaid kan worden. Hoewel de omschrijving van de keuzes kort en bondig gehouden is in deze handleiding, is het gehele proces na te lezen in het verantwoordingsdocument (zie Oplevering). - Hosting
Om het prototype in een productieomgeving te kunnen draaien, hebben we verschillende configuratiebestanden beschikbaar gesteld. In dit hoofdstuk worden deze en de samenhang ertussen toegelicht. Hiermee kan het prototype in een productieomgeving gedraaid worden ter evaluatie. - Resultaat en toekomst
Aangezien het project heeft geresulteerd in een werkend prototype, omschrijven we dit resultaat in deze handleiding. Tevens beschrijven we hier welke zaken wellicht in de toekomst toegevoegd zouden kunnen worden aan het project en welk onderhoud erbij komt kijken.
Je zult af en toe nog de afkorting RoTT tegenkomen, dit staat voor Research on Trends in Technology en is de naam van het vak waarvoor dit onderzoeksopdracht uitgevoerd is.
Meer informatie hierover te vinden op de online leeromgeving over programmatisch toetsen.
Projectgroep
De oorspronkelijke (en op het moment van schrijven enige) projectgroep die aan dit project gewerkt heeft bestaat uit:
- Ahmed Benhajar (21024154, A.Benhajar@student.hhs.nl)
- Edwin Ros (19137052, E.Ros@student.hhs.nl)
- Jennifer Goudswaard (21155496, J.Goudswaard@student.hhs.nl)
- Marjo Salo (21146942, M.J.Salo@student.hhs.nl)
- Sander in 't Hout (15126463, S.A.intHout@student.hhs.nl)
Probleemstelling
In dit hoofdstuk staan we kort stil bij de probleemcontext (de opdrachtgever, het vraagstuk en waardoor het vraagstuk is ontstaan), de eerste stappen die we gevolgd hebben om het probleem helder te krijgen en de hoofdvraag en deelvragen die we gevormd hebben om ons onderzoek te kunnen starten.
Context
Een belangrijk strategisch thema van de Haagse Hogeschool is de kwaliteit van onderwijs en onderzoek. Een van de concrete methodes die de school noemt in publicaties over dit thema is programmatisch toetsen. Met programmatisch toetsen kan de gehele ontwikkeling van een student beter gevolgd worden, doordat er niet enkel getoetst wordt aan het einde van een vak (waarna enkel op basis van vaak 1 toets een zak/slaag beslissing gemaakt wordt). Een belangrijk speerpunt van programmatisch toetsen is namelijk het verzamelen van veel datapunten om deze zak/slaag beslissing te kunnen maken.
Binnen de school wordt er gebruik gemaakt van Brightspace als LMS (Learning Management System). Op dit moment wordt Brightspace voornamelijk gebruikt voor het aanbieden van lesstof. Echter biedt Brightspace ook de mogelijkheid om digitaal toetsen af te nemen. Een minderheid van docenten op de school maakt reeds gebruik van deze mogelijkheid om de voortgang van studenten te meten.
Het regelmatig tussentijds digitaal toetsen van studenten kan een manier zijn om aan eerdergenoemde datapunten te komen. Echter betekent dit meer werkdruk voor docenten. Immers zouden zij meer toetsen moeten maken. Gezien de opkomst van generatieve AI (bijvoorbeeld ChatGPT) en de mogelijkheden die dit biedt, is de vraag ontstaan of generatieve AI hier iets in kan betekenen. Het is reeds mogelijk om lesstof en een onderwerp in te voeren in ChatGPT en met deze invoer toetsvragen te genereren. Echter is dit niet voor iedere docent weggelegd om te doen, en kan ChatGPT niet helpen om deze vragen in Brightspace te krijgen.
Om deze redenen is door dr. ir. Marinus Maris (M.Maris@hhs.nl), onze opdrachtgever, deze vraag bij ons neergelegd.
Orientatie
Tijdens een brainstormsessie hebben we alle gedachtes die we bij het project kregen, op papier gezet:
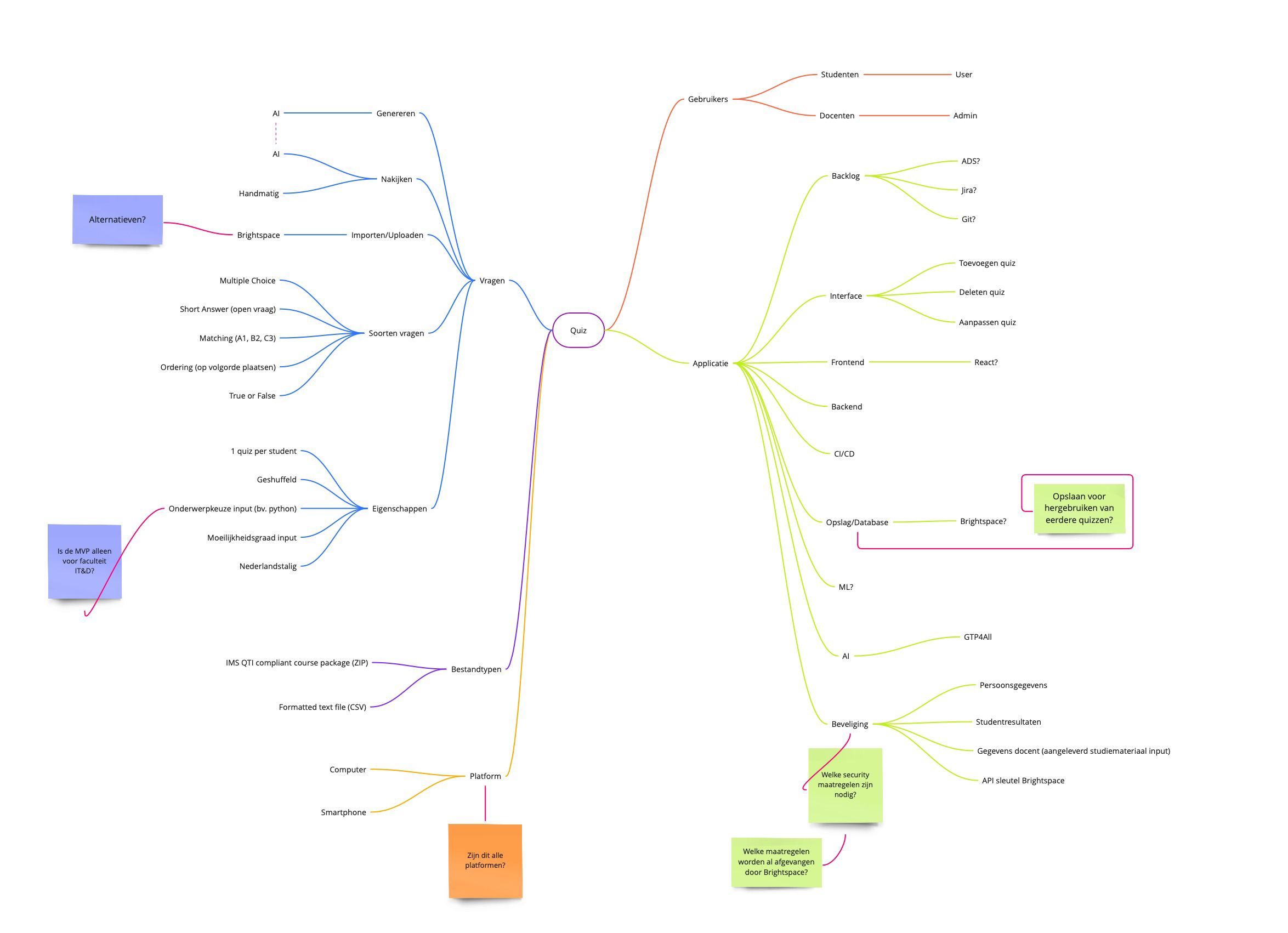
Om na te gaan bij de opdrachtgever welk gedeelte van het proces van een quiz maken en afnemen, hij graag ondersteund zou zien door middel van een technische oplossing, hebben we een tweetal flowcharts gemaakt. De bovenste toont het proces zoals wij begrepen hadden. De onderste toont het proces, maar dan ondersteund door AI.
Na voorleggen van deze flowcharts bleek dit inderdaad te zijn wat de opdrachtgever in gedachte had.

Hoofdvraag en deelvragen
De orientatie heeft de volgende hoofdvraag opgeleverd:
Op welke wijze kan een generatieve AI-applicatie toetsing via Brightspace automatiseren voor de docenten HBO-ICT aan de Haagse Hogeschool, om het leerproces van studenten te bevorderen?
Met de volgende deelvragen:
- Welke toetsvormen zorgen voor lesstofretentie bij de studenten in de klas?
- Welk bestaand AI-model kan het beste automatisch toetsvragen met bijbehorende antwoorden genereren op basis van ingevoerde lesstof?
- Welke combinatie van prompts kan toetsvragen met bijbehorende antwoorden uit de ingevoerde lesstof genereren binnen de generatieve AI-applicatie?
- Welke mogelijkheden biedt Brightspace om de automatische gegenereerde toetsvragen met bijbehorende antwoorden te importeren?
De insteek van de paper verschilt iets van de insteek van het gehele onderzoek. Het AI-stuk uit het onderzoek heeft de hoofdrol gekregen in de paper. Hiervoor hebben we ons beperkt tot deelvraag 1 t/m 3.
De reden voor deze keuze is dat het prototype en de export naar Brightspace beperkte wetenschappelijke waarde hebben.
Requirements
Om het onderzoek en de benodigde functionaliteiten van het prototype af te bakenen hebben we de MoSCoW-methode gebruikt.
Must haves
| Categorie | ID | Eis |
|---|---|---|
| Algemeen | A1 | De applicatie moet de docent in staat stellen om quizvragen en -antwoorden te laten genereren, zodat deze quizvragen kunnen worden gebruikt als input in Brightspace. |
| Algemeen | A2 | De applicatie moet integratie ondersteunen met Brightspace, zodat er middels een backend data uitwisseling mogelijk is. |
| Algemeen | A3 | De applicatie moet voldoen aan GDPR-normen, zodat studenteninformatie niet wordt opgeslagen of verwerkt. |
| Algemeen | A4 | De applicatie moet een duidelijke en simpele interface hebben voor docenten, zodat het eenvoudig in gebruik is. |
| Algemeen | A5 | De applicatie moet git-integratie ondersteunen voor versiebeheer. |
| Algemeen | A6 | Als ontwikkelaar, wil ik toegang hebben tot een developers manual (overdrachtsdocument), zodat ik snel aanpassingen kan maken en documentatie kan raadplegen. |
| Algemeen | A7 | Als docent, wil ik een user manual (gebruikershandleiding) hebben zodat ik op de hoogte ben van alle mogelijkheden van de applicatie. |
| Algemeen | A8 | De applicatie moet toegankelijk zijn voor de HBO-ICT docenten en beheerders van de Haagse Hogeschool, zodat na afronding van het prototype het door de Haagse Hogeschool in beheer kan worden genomen. |
| Algemeen | A9 | De applicatie moet compatibel zijn met de meeste moderne browsers (Chrome, Firefox, Edge), zodat de applicatie via webbased kan worden gehost. |
| AI-Model | M1 | Als docent, wil ik quizvragen en -antwoorden uit de lesstof van mijn cursus kunnen genereren, zodat de inhoud van de quiz overeenkomt met mijn cursus. |
| AI-Model | M2 | Als docent, wil ik dat mijn ingevoerde cursusmaterialen binnen de systemen van de Haagse Hogeschool blijven, zodat ik weet dat eventuele gevoelige informatie uit de cursusmaterialen niet bij een derde partij terechtkomt. |
| AI-Model | M3 | Als docent, wil ik quizvragen en -antwoorden in het Nederlands kunnen genereren, zodat de taal van de quiz overeenkomt met de taal van de cursus. |
| AI-Model | M4 | Als docent, wil ik dat de gegenereerde antwoorden correct zijn, zodat ik ze kan gebruiken bij het nakijken van de quiz. |
| AI-Model | M5 | De applicatie moet op meerdere systemen bruikbaar zijn voor zowel MacOS als Windows-gebruikers, zodat de applicatie op meerdere besturingssystemen kan worden gebruikt. |
| UI-Quiz Generator | U1 | Als docent, wil ik via een grafische interface de applicatie gebruiken, zodat ik quizvragen kan genereren. |
| UI-Quiz Generator | U2 | Als docent, wil ik een quiz kunnen exporteren met de quizvragen en -antwoorden, zodat deze in het gewenste Brightspace CSV-formaat kan worden ingelezen. |
| Toetsvorm | T1 | Als docent, wil ik dat de applicatie een quiz genereert die bestaat uit een combinatie van minimaal drie quizvraag-soorten, zodat meerdere aspecten van het denkvermogen getoetst wordt over de eerder aangereikte lesstof. |
| Toetsvorm | T2 | Als docent, wil ik dat de applicatie een short answer quizvraag genereert die uit minimaal één regel en maximaal twee regels tekst bestaat, zodat er genoeg context kan worden gegeven over het antwoord op de quizvraag op basis van kernwoorden. |
| Toetsvorm | T3 | Als docent, wil ik dat de applicatie een true/false quizvraag genereert uit twee antwoordmogelijkheden bestaat, zodat er een duidelijk onderscheid kan worden gemaakt tussen goed en fout. |
| Toetsvorm | T4 | Als docent, wil ik dat de applicatie een multiple choice quizvraag genereert die uit minimaal vier- en maximaal zes antwoordopties bestaat, zodat er een grotere kans is dat er een keuze gemaakt wordt op kennis in plaats van kans. |
| Toetsvorm | T5 | Als student, wil ik feedback (het correcte antwoord) ontvangen over de antwoorden van de gemaakte quiz, zodat ik kan leren van de gemaakte fouten en mijn kennis kan verbeteren. |
Alle genoemde requirements zijn gerealiseerd.
Should haves
| Categorie | ID | Eis |
|---|---|---|
| Algemeen | A10 | De applicatie moet een schaalbare backend hebben voor minimaal 2000 gebruikers, zodat het prototype meerdere gebruikers tegelijkertijd kan ondersteunen. |
| Algemeen | A11 | De applicatie moet snel en responsief zijn, met een opstarttijd van minder dan 2 seconden (uitgezonderd van generatieve functies), zodat de verwerking van een request tot aan bijna realtime verloopt. |
| Algemeen | A12 | De applicatie moet snel en responsief zijn, met een generatieve laadtijd van minder dan 5 minuten, zodat de verwerking van een request tot aan bijna realtime verloopt. |
| AI-Model | M6 | Als docent, wil ik dat de quizvragen en -antwoorden minimaal op Nederlands taalniveau 3F geschreven zijn. |
| AI-Model | M7 | De applicatie moet de eerste quizvraag en -antwoord binnen 5 seconden kunnen tonen op het scherm. |
| Prompting | P1 | De applicatie moet een prompt meekrijgen, zodat de gewenste output in het opgegeven formaat wordt gegenereerd. |
| UI-Quiz Generator | U3 | Als docent, wil ik een gegenereerde quizvraag opnieuw kunnen genereren, zodat ik een vraag kan aanpassen. |
| UI-Quiz Generator | U4 | Als docent, wil ik een gegenereerde quizvraag desgewenst kunnen bewerken, zodat ik zelf controle heb over de kwaliteit van de quizvragen. |
| UI-Quiz Generator | U5 | Als docent, wil ik een gegenereerde quizvraag kunnen verwijderen, zodat ik zelf controle heb over de kwaliteit van de quizvragen. |
| Usability | G1 | Als docent, wil ik binnen de applicatie binnen enkele klikken (maximaal 5) komen tot de gewenste quiz. |
| Usability | G2 | Als docent, wil ik dat de applicatie een intuïtieve, eenvoudig te navigeren interface biedt, zodat het eenvoudig in gebruik is voor diverse docenten van diverse achtergronden. |
| Backend | B1 | Als docent, wil ik dat de gegenereerde quiz wordt opgeslagen in een database, zodat ik deze kan raadplegen of hergebruiken. |
| Backend | B2 | Als docent, wil ik dat de backend een CSV-generator heeft, zodat ik de output kan opslaan in quizzen in Brightspace. |
| Backend | B3 | De applicatie moet binnen 3 seconden een CSV-bestand genereren, bij maximaal 25 vragen, zodat de gebruiker per direct een quiz kan uploaden naar Brightspace. |
Could haves
| Categorie | ID | Eis |
|---|---|---|
| Algemeen | A13 | De applicatie moet ondersteuning bieden voor Engelstalige quizzen, zodat dit prototype ook voor Engelstalige lesstof kan worden gebruikt. |
| Algemeen | A14 | De applicatie moeten kunnen draaien op apparaten met lagere specificaties, zodat het prototype ook op oudere laptops kan worden gebruikt. |
| Algemeen | A15 | De applicatie moet (in Brightspace) een dashboard hebben die realtime de resultaten/voortgang per student weergeeft, zodat de voortgang/progressie per student inzichtelijk wordt gemaakt voor de docent en student. |
| AI-Model | M8 | Als docent, wil ik een niveau kunnen aangeven voor de quizvragen, zodat ik weet dat de quiz aansluit bij het niveau van de studenten. |
| Prompting | P2 | Als docent, wil ik weten wanneer er geen goede vragen gegenereerd worden en waarom dat zo is, zodat ik eventueel mijn prompt of vraagstelling aan kan passen. |
| UI-Quiz Generator | U6 | Als docent, wil ik de mogelijkheid hebben om de taal van de applicatie te wijzigen tussen Nederlands en Engels, zodat ik de interface in de taal van mijn voorkeur kan gebruiken. |
| UI-Quiz Generator | U7 | Als docent, wil ik een semester selecteren, zodat ik voor diverse studievakken quizzen kan genereren. |
| UI-Quiz Generator | U8 | Als docent, wil ik links van de interface een overzicht in tree structuur met semesters voor een overzicht van de lesstof. |
| Usability | G3 | Als docent, wil ik dat de applicatie gebruik maakt van de HHS-kleuren zodat deze past binnen de HHS-huisstijl. |
Won't haves
| Categorie | ID | Eis |
|---|---|---|
| Algemeen | A16 | De applicatie zou ondersteuning moeten bieden voor donkere modus, zodat de interface oogvermoeidheid verminderd. |
Design
Om het prototypen goed te laten verlopen is voorbereiding nodig geweest. De belangrijkste designs die we gemaakt hebben zijn dan ook toegelicht in de subhoofdstukken van dit hoofdstuk.
Database-design
We zijn aan het begin van het project erg ambitieus te werk gegaan. Niet wetende hoeveel het onderzoek en het schrijfwerk in beslag zou nemen, hadden we bedacht dat het nuttig zou zijn als de applicatie de gegenereerde vragen zou kunnen opslaan. Daarnaast gingen we er op dat moment nog van uit dat de applicatie lokaal bij de gebruiker zou draaien (in plaats van gehost op een server).
Daaruit ontstond een simpel ERD dat slechts voorziet in het opslaan van de gegenereerde quizzes:
erDiagram
quizzes {
integer id PK
varchar(50) name
}
questions {
integer id PK
varchar(255) title
varchar(255) question
integer points
varchar(255) options
varchar(255) hint
varchar(255) feedback
integer quiz_id FK
varchar(10) question_type FK
}
question_types {
varchar(10) name PK
}
quizzes ||--o{ questions : contains
question_types ||--o{ questions : has
Hierna bedachten we dat het project mogelijk gehost zou worden, waarmee het noodzakelijk wordt om security te implementeren. Zodoende hebben we users toegevoegd. Daarnaast wilden we uitzoeken of het mogelijk is de embeddings op te slaan van de ingevoerde documenten en deze documenten in een collectie op te slaan. Dit zou mogelijk maken dat je zonder al teveel moeite opnieuw dezelfde (collectie van) documenten kunt gebruiken om een nieuwe quiz te genereren, of gemakkelijk aan een vorige quiz kunt sleutelen.
In het volgende ERD zijn dan ook de tabellen users, collections, documents en embeddings toegevoegd:
erDiagram
quizzes {
integer id PK
varchar(50) name
integer user_id FK
}
questions {
integer id PK
varchar(255) title
varchar(255) question
integer points
varchar(255) options
varchar(255) hint
varchar(255) feedback
integer quiz_id FK
varchar(10) question_type FK
}
question_types {
varchar(10) name PK
}
users {
integer id PK
varchar(80) first_name
varchar(80) last_name
varchar(80) username UK
varchar(80) password
}
collections {
integer id PK
varchar(255) title
varchar(255) metadata
integer user_id FK
}
collections_quizzes {
integer collection_id FK
integer quiz_id FK
}
documents {
integer id PK
varchar(255) text
}
embeddings {
integer id PK
varchar embedding
varchar(255) document
varchar(255) metadata
integer collection_id FK
integer document_id FK
}
quizzes ||--o{ questions : contains
question_types ||--o{ questions : has
users ||--o{ quizzes : owns
users ||--o{ collections : owns
collections ||--o{ collections_quizzes : contains
quizzes ||--o{ collections_quizzes : part_of
collections ||--o{ embeddings : embeds
documents ||--o{ embeddings : has
In het prototype
Tijdens het bepalen van de prioriteiten, is persistentie minder belangrijk gebleken. Hierdoor hebben we gekeken naar simpelere oplossingen voor de eerste versie van het prototype. Daarom hebben we uiteindelijk besloten de ERD's te archiveren en te gaan voor een tijdelijke persistentie middels Redis.
Wanneer je een quiz genereert wordt deze tijdelijk bewaart, samen met de embedding in Redis. Na een paar uur wordt deze data weer verwijderd. Toegang tot de quiz wordt verleend via de URL waar de applicatie automatisch heen navigeert wanneer de quiz gemaakt is. Deze URL bevat dan ook het quiz_id.
C4-diagrammen
Om de technische structuur van de applicatie uit te leggen, hebben we een tweetal C4-diagrammen gemaakt. Het Context-model toont onze applicatie als enkel blok en laat enkel de verhoudingen tussen de gehele systemen zien. Het Container-diagram laat ook zien uit welke onderdelen de H-AI-applicatie bestaat.
Andere typen C4-diagrammen zijn weggelaten omdat deze worden afgeraden1 2, bijvoorbeeld omdat ze:
- Automatisch gegenereerd zouden kunnen worden, of
- Weinig tot niets bijdragen voor het begrijpen van de structuur van de applicatie.
De blauwe componenten zijn componenten die door ons gebouwd zijn en/of gehost worden. De grijze componenten zijn componenten waar we mee te maken hebben, maar geen zeggenschap over hebben.
Context diagram
C4Context
UpdateLayoutConfig($c4ShapeInRow="2")
Enterprise_Boundary(b0, "De Haagse Hogeschool") {
Person(teacher, "Docent", "Een docent van de Haagse Hogeschool.")
System_Ext(Brightspace, "Brightspace", "LMS waar onder meer quizzes mee afgenomen kunnen worden.")
Rel(teacher, Brightspace, "Importeert geëxporteerde quizvragen in")
System(H-AI, "H-AI", "Staat docenten toe om geautomatiseerd quizvragen te genereren en naar Brightspace te exporteren.")
Rel(teacher, H-AI, "Genereert quizvragen met")
}
Container diagram
Hoewel we ook werken met Docker-containers, moet het begrip 'Container' in de context van C4-diagrammen hier niet mee verward worden.
C4Container
UpdateLayoutConfig($c4ShapeInRow="2")
Enterprise_Boundary(b0, "De Haagse Hogeschool") {
Person(teacher, "Docent", "Een docent van de Haagse Hogeschool.")
Rel(teacher, frontend, "Gebruikt om quizzes te genereren")
System_Ext(Brightspace, "Brightspace", "LMS waar onder meer quizzes mee afgenomen kunnen worden.")
System_Boundary(hai, "H-AI") {
Container(frontend, "Frontend", "Javascript (React)", "Provides all the internet banking functionality to customers via their web browser.")
Container(backend, "Backend", "Python (FastAPI, Celery, LangChain)", "Verzorgt het genereren van quizzes middels een wachtrij en maakt quizzes beschikbaar voor het frontend.")
Rel(frontend, backend, "Maakt API-calls naar")
ContainerDb(redis, "Redis", "", "Slaat gegenereerde quizzes op en document vectoren.")
Rel(backend, redis, "Slaat gegenereerde vragen en document vectoren op in")
Container(ollama, "Ollama", "", "Biedt API om met LLM's te werken")
Rel(backend, ollama, "Laat vragen genereren door")
}
Rel(teacher, Brightspace, "Importeert geëxporteerde quizvragen in")
}
UI/UX-design
Op het moment dat we bedacht hadden wat we zouden kunnen maken voor de opdrachtgever, hebben we UI/UX-designs gemaakt met Draw.io. Deze designs hebben we voorgelegd aan de opdrachtgever, met als doel na te gaan of dit inderdaad zou bijdragen aan het probleem wat centraal staat. De gemaakte designs staan op hiervoor bestemde git repository.
We zijn ambitieus van start gegaan, met ontwerpen welke ook persoonlijke opslagmogelijkheden tonen voor gebruikers (hier te vinden). Hiermee zouden de gegenereerde quizzes en lesmateriaal bewaard kunnen worden voor hergebruik. Zoals te lezen in onze requirements had persistentie echter niet de hoogste prioriteit. Daarom hebben we deze ontwerpen in de ijskast geplaatst en zijn we aan de slag gegaan met simpelere varianten gaan maken (hier te vinden).
Deze simpelere varianten zijn de basis geworden van de applicatie zoals hij nu staat. Voor kleuren en vormen hebben we afgekeken bij Brightspace-instance1 van de HHS en de huisstijl van de HHS2, zodat we een herkenbare interface kunnen tonen aan gebruikers.
Omwille van de eenvoud van de applicatie, beperkte designkennis en de voorbeelden die we reeds tot onze beschikking hadden, hebben we gekozen om geen high fidelity-designs te maken.
Impressie van de designs
De designs kunnen vrij ingezien worden door de .drawio-bestanden uit eerdergenoemde repository te openen in Draw.io. Toch willen we enkele belangrijke designs hier uitlichten.
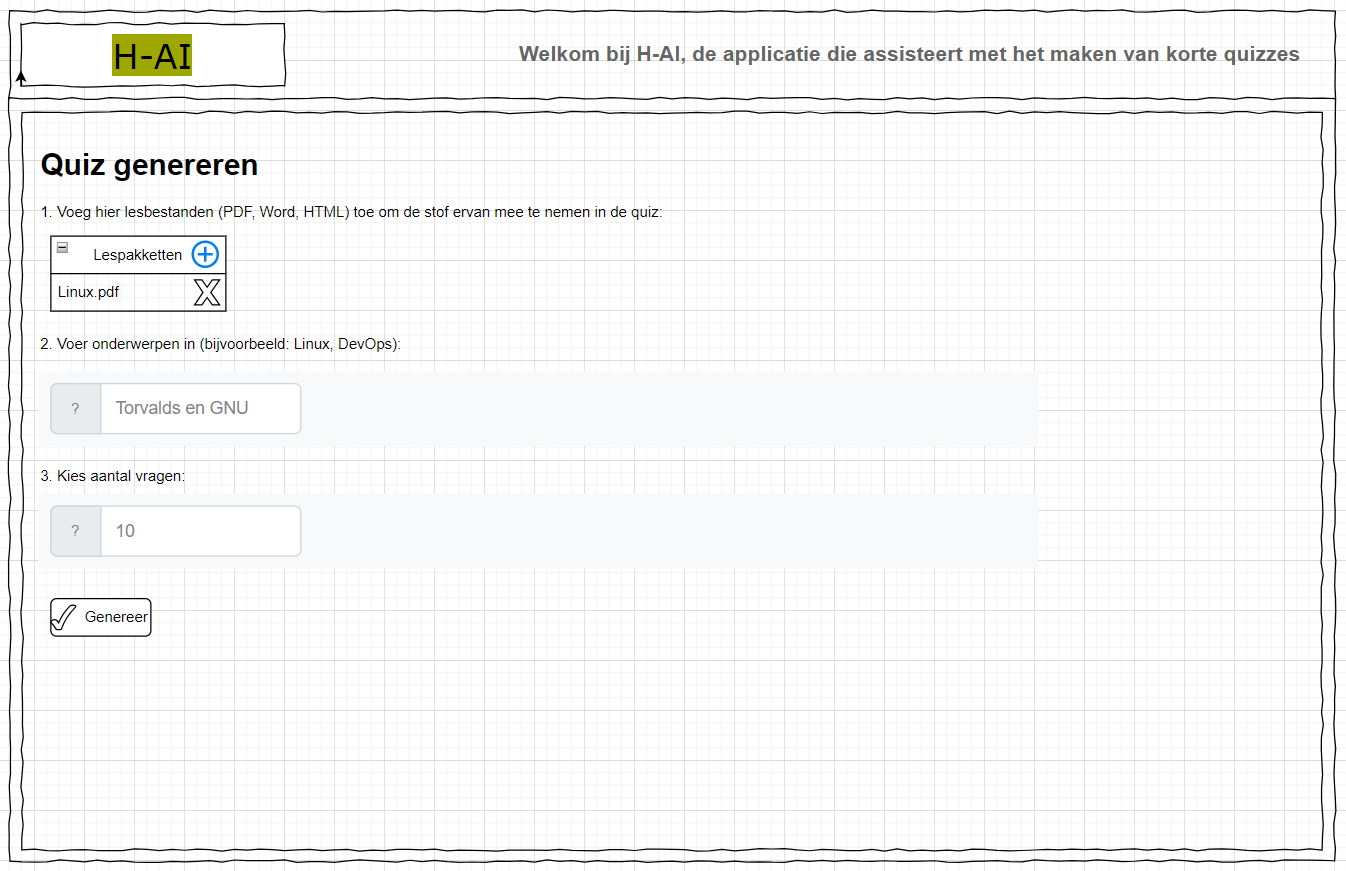
Quiz genereren
De volgende afbeelding toont de UI van het Quiz genereren-scherm. Aangezien er geen inlogmogelijkheid is, is dit ook het startscherm van de applicatie.
Quiz inzien en exporteren
Wanneer het genereren klaar is, moet men op dit scherm terecht komen. Hier worden de vragen getoond met enkele eenvoudige bewerkingsfuncties. Deze bewerkingsfuncties zijn op vraagniveau bijvoorbeeld:
- Quizvraag hergenereren, dit genereert een nieuwe vraag van hetzelfde type ter vervanging van de vraag.
- Quizvraag verwijderen, dit verwijdert de vraag.
Gebruik van de designs in het prototype
Vrijwel alle functies die te zien zijn in de designs zijn geimplementeerd, enkele functies vielen na het toepassen van priorering middels de MoSCoW-methode af voor het eerste prototype:
- De 'Genereer extra vraag'-functie.
- De 'Alles opnieuw genereren'-functie.
- Vragen bewerken (dit kan de gebruiker wel in Brightspace doen).

Keuzes
Om het prototypen goed te laten verlopen is voorbereiding nodig geweest. De belangrijkste keuzes die we gemaakt hebben zijn dan ook toegelicht in de subhoofdstukken van dit hoofdstuk.
Frontend en backend keuzes
In dit hoofdstuk kun je de criteria vinden welke wij gebruikt hebben om frameworks en libraries te kiezen.
Deze tabellen zijn met toelichting te lezen in ons verantwoordingsdocument.
Talen en frameworks
| Tool | Naam | Omschrijving |
|---|---|---|
| LLM Manager | Ollama | Een LLM-manager die het eenvoudig downloaden en runnen van Large Language models via de command line mogelijk maakt. Uitgebreide integratie met het LangChain framework via ChatOllama. |
| LLM framework | LangChain | Een open-source LLM-framework beschikbaar voor Javascript en Python. LangChain biedt veel opties voor RAG-taken, zoals document loaders en embedding models. |
| Programmeertaal | Python | Een veelzijdige programmeertaal voor machine learning en AI-taken. |
| In-memory data store | Redis | Een key-value database, cache en vector store voor het opslaan van quizzen en vectoren uit cursusmaterialen. |
| API specificatie | OpenAPI/Swagger | Tools voor gestructureerd specificeren en visualiseren van API-endpoints. |
| Queue systeem | Celery | Een queue systeem om de backend responsief te houden. |
| Queue systeem dashboard | Celery flower | Een dashboard voor het monitoren van de Celery queue. |
| Containerisatietool | Docker | Containerisatietool voor het platform-agnostisch uitrollen van applicaties. |
Backend-framework
| Frameworks | Python | RESTful API | Data validation | Swagger integratie | Unittest ondersteuning | Queuesysteem ondersteuning | Uitgebreide documentatie | WebSockets of Server-Side Events (SSE) |
|---|---|---|---|---|---|---|---|---|
| Django REST | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Flask REST | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ | ❌ |
| FastAPI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pyramid | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Falcon | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| Bottle | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Eve | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ |
| Sanic | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Tornado | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Hug | ✅ | ✅ | ❌ | ❌ | ✅ | ❌ | ✅ | ❌ |
| TurboGears | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ | ✅ | ❌ |
Op basis van deze vergelijking hebben we gekozen voor FastAPI.
Frontend-framework
| Frameworks | SPA | Uitgebreide documentatie |
|---|---|---|
| Vue.js | ✅ | ✅ |
| React | ✅ | ✅ |
| Angular | ✅ | ✅ |
| Svelte | ✅ | ❌ |
| Solid | ✅ | ❌ |
| Lit | ✅ | ❌ |
| Qwik | ✅ | ❌ |
| Ember.js | ✅ | ❌ |
Op basis van deze vergelijking en op basis van de bestaande kennis binnen onze groep, hebben we gekozen voor React.
CSS-framework
Om te helpen de styling sneller te kunnen bouwen hebben we enkele CSS-frameworks bekeken:
| Bootstrap | Material UI | Radix UI | shadcn | |
|---|---|---|---|---|
| Versie | 5.3.3 | 6.1.5 | Oktober 1, 2024 | August 2024 |
| Responsive | ✅ | ✅ | ✅ | ✅ |
| React-ondersteuning | ⚠️ (Middels React Bootstrap) | ✅ | ✅ | ✅ |
| Customization opties | Kleur, fonts | Kleur, fonts | Accentkleur, radius, schaal | Kleur, radius |
| Customization methode | Variable overrides middels Sass files | Theme overrides (tool: mui-theme-creator), of global CSS overrides | Via playground | CSS variabelen of Tailwind CSS utility classes |
| Menu bar (zoals Brightspace) | ✅ (Navbar) | ✅, (App bar) | ✅, (Navigation Menu) | ✅, (Navigation Menu) |
| Card | ✅ | ✅ | ✅ | ✅ |
| Breadcrumbs | ✅ | ✅ | ❌ | ✅ |
| Tree view | ❌ | ✅ | ❌ | ❌ |
| Visuele gelijkenis met Brightspace (out of the box) | ✅ | ⚠️ (In zekere mate) | ❌ | ❌ |
Op basis van deze vergelijking hebben we gekozen voor Material UI.
Dataopslag
In dit hoofdstuk kun je de criteria vinden welke wij gebruikt hebben om een database te kiezen.
| Vector embeddings | Gestructureerde data | LangChain support | Open source | |
|---|---|---|---|---|
| MySQL | ✅ | ✅ | ❌ | ✅ |
| Milvus | ✅ | ❌ | ✅ | ✅ |
| PostgreSQL met pgvector | ✅ | ✅ | ✅ | ✅ |
| ClickHouse | ✅ | ✅ | ✅ | ✅ |
Het doel van deze vergelijking was om een database te vinden voor zowel vector embeddings (voor de embedding van ingevoerd lesmateriaal) als gestructureerde data (opgeslagen quizzes, gebruikers, enz.). Omwille van de tijd en na een kritische blik op de functionaliteiten middels de MoSCoW-methode, is gekozen om geen quizzes en lesmateriaal te persisteren en gebruik te maken van tijdelijke opslag middels Redis.
Deze tabel is met toelichting te lezen in ons verantwoordingsdocument.
AI-modellen
Binnen dit project hebben we veel keuzes moeten maken voor het AI-gedeelte. In dit hoofdstuk lichten we de opties toe die we bekeken hebben, en leggen we uit hoe de keuzes tot stand zijn gekomen.
Waarom geen service (bijvoorbeeld OpenAI/ChatGPT)
Tijdens een van de eerste besprekingen met de opdrachtgever kwam ter sprake dat het systeem rekening moet houden met auteursrechten op lesmateriaal en privacy van studenten. Aangezien we reeds hadden gezien dat we bijvoorbeeld middels GPT4ALL1 LLM's kunnen draaien op onze eigen computer, besloten we onze focus te leggen op het lokaal draaien van LLM's.
Om te testen of het gebruiken van documenten daadwerkelijk mogelijk was, hebben we GPT4All opgestart, een model geinstalleerd, lesmateriaal van Brightspace toegevoegd en gevraagd of de LLM er enkele vragen over kon genereren. Hieruit kwam een resultaat was voldoende aanleiding gaf om vol op deze optie te gaan.
Dankzij deze keuze:
- Besparen we de HHS licentiekosten op (immers vrijwel altijd stevig betaalde) services zoals OpenAI/ChatGPT.
- Hoeven we geen onderzoek te doen naar mogelijke privacybewaren die volgen uit de voorwaarden van externe services.
- Blijft de HHS alle data in beheer houden, er gaat niets naar de cloud aangezien alle componenten lokaal draaien.
- Konden we ons onderzoek beperken tot lokale LLM's, waarmee er meer tijd vrij kwam om de kwaliteit te waarborgen.
LLM
Wanneer je uitzoekt hoe LLM's lokaal gedraaid kunnen worden, kom je al snel op het bekende LLaMA van Meta (het bedrijf achter Facebook). We hebben dan ook onder andere dit model vergeleken met enkele andere. De criteria waar we onze modellen langs hebben gelegd waren:
- Open, lokaal downloadbaar model.
- Hoge context grootte i.v.m. RAG (Retrieval Augmented Generation).
- Ondersteuning voor de Nederlandse taal.
- Kwalitatief hoogwaardige output.
Naast LLaMA 3.1 8B, hebben we ook Aya 8B, Aya Expanse en GEITje 7B meegenomen in de vergelijking.
Na verschillende tests in een prototype met RAG bleken de modellen van Aya (waarbij Aya Expanse nog iets beter) het best getrained te zijn op de Nederlandse taal (minste taalfouten), en het best onze systeem prompt (met o.a. de opdracht voor de LLM, het gewenste output dataformaat, etc.) te volgen. De keuze is dan ook hier op gevallen.
Embedding model
Iets minder bekend zijn modellen voor embedding2. Tijdens het testen van generatieve modellen is de vraag ontstaan of het generatieve model om zou kunnen gaan met langere teksten (cursusmaterialen) als input in de prompt, dus zonder enige filter. Of zou het model zelf alleen relevante stukken uit de materialen kunnen gebruiken, en de rest negeren?
Tijdens het testen van de modellen bleek dat de beste output mét een speciaal embedding model wordt gegenereerd.
De werking van een embedding model is, in het kort, als volgt:
- De cursusmaterialen én het onderwerp worden doorgegeven naar het embedding model.
- Het embedding model converteert de cursusmaterialen in vector embeddings en slaat deze op in de vector store (in dit geval, Redis).
- Het embedding model haalt vervolgens alleen die stukken uit de vector store, die bij het onderwerp passen.
- Deze stukken worden weer geconverteerd in tekst en doorgegeven aan het generatief model als context.
- Dit resulteert in een kortere, maar relevantere system prompt, een daarbij in betere output.
Omwille van de tijd die beschikbaar was voor het project, en het feit dat veel embedding modellen niet getrained zijn op de Nederlandse taal, hebben we slechts bge-m3 getest.
Draaien in dev omgeving
Dit hoofdstuk omschrijft hoe het prototype lokaal gedraaid kan worden. Hoewel het project zou moeten kunnen draaien op iedere computer met 16 GB RAM (en ongeveer 20 GB vrije schijfruimte voor ontwikkeltools en LLM's), is snelheid daarmee niet gegarandeerd. Meer hierover in het hoofdstuk Hardware.
Backend
Het backend woont in de rott-backend-repository. Doe een Git clone en voer de volgende stappen uit:
- Open de map waarin je net gecloned hebt.
- Maak een leeg bestand aan genaamd
app.log. - Kopieer het
.env-example-bestand naar.env. - Pas in het
.env-bestand de regelOLLAMA_BASE_URL=<http://ollama:11434>aan naarOLLAMA_BASE_URL=http://host.docker.internal:11434. Dit is noodzakelijk omdat de example config er van uit gaat dat Ollama in Docker draait. Met de aanpassing kan het backend verbinden naar de instance van Ollama die direct op de host draait. - Draai het volgende commando in een terminal:
docker compose up.
Het backend en de noodzakelijke workers zouden nu moeten draaien in Docker! Je kunt bij het backend door te navigeren naar http://localhost:8000/docs te openen in je webbrowser.
Ollama
Voor het ontwikkelen adviseren we Ollama buiten Docker te draaien. In de standaard docker-compose.yml van het backend is Ollama dan ook niet opgenomen. Download en installeer de juiste versie gegeven je besturingssysteem en je CPU-architectuur.
Installeer de juiste modellen in Ollama door de volgende commando's in een terminal te draaien nadat je Ollama gestart hebt (en deze dus op de achtergrond actief is):
ollama pull aya-expanse
ollama pull bge-m3
Je hoeft verder niets met Ollama te doen anders dan hem actief te laten, het backend zal op de achtergrond Ollama aansturen.
Frontend
Het backend woont in de rott-frontend-repository. Doe een Git clone.
Draai vanaf een terminal (cd eerst naar de Handover-map) de volgende commando's:
npm i
npm start
Het frontend zou nu moeten draaien! Je kunt bij het frontend door te navigeren naar http://127.0.0.1:3000 te openen in je webbrowser.
Werken aan deze handleiding
Deze handleiding woont in de rott-docs-repository. Doe een Git clone. Vervolgens vindt je hem in het mapje Handover.
Draai vanaf een terminal (cd eerst naar de Handover-map) de volgende commando's (let op: het kan even duren):
docker build . -t h-ai-handover-manual
docker run --name h-ai-handover-manual --volume .:/book-src -p 127.0.0.1:8001:8001 h-ai-handover-manual
Je kunt de handleiding nu in je webbrowser openen via http://localhot:8001.
Stop de Docker container met docker stop h-ai-handover-manual en start hem opnieuw met docker start h-ai-handover-manual wanneer je weer verder wil werken.
Deze setup is handig voor het ontwikkelen, omdat de container automatisch zal reageren op wijzigingen die je maakt aan de .md-bestanden. In de meeste gevallen zal je webbrowser ook automatisch verversen als je het boek open hebt.
Productie?
Een variant van bovenstaande setup, meer geschikt om in productie te gebruiken voor evaluatie- en demodoeleinden, is omgeschreven in het hoofdstuk Docker-setup.
Docker-setup
Zoals toegelicht in het hoofdstuk Draaien in dev omgeving, hebben we Docker op Windows en macOS gebruikt. De Dockerfile- en docker-compose.yml-bestanden hiervoor staan in de betreffende repositories. Deze bestanden kunnen ook helpen om het project in productie te zetten.
Hiervoor is wel aanvullende configuratie nodig. Deze staat reeds ter demo op de server die we van school gekregen hebben, maar lichten we ter archivering en toelichting ook hier uit.
Verwachte bestandsstructuur
Alle Docker-configuratie is gebouwd op relatieve paden. Hierdoor maakt het niet uit waar je de verwachte bestandsstructuur hebt. De structuur zelf is wel belangrijk. Binnen de huidige server staan deze bestanden in de Linux-profielmap: /home/groep2.
[root]/Sources/rott-backend # Clone van de backend repo.
[root]/Sources/rott-backend/.env # Backend configuratie, een kopie van de `.env.example` voldoet om te starten.
[root]/Sources/rott-backend/app.log # Log-bestand, maak dit bestand leeg aan VOOR je het project start, bijvoorbeeld met het commando `touch app.log`.
[root]/Sources/rott-frontend # Clone van de frontend repo.
[root]/Sources/rott-docs # Clone van de docs repo.
[root]/compose.yml # Docker Compose file met HTTP(S) reverse proxy, frontend en docs.
[root]/override.yml # Docker Compose file met productie-overrides op de Docker-bestanden uit de repo.
Configuratie
De volgende Docker Compose-file combineert de Docker Compose-file uit de backend repo met configuratie om:
- Alle services (frontend, backend en docs) beschikbaar te maken via HTTPS middels Traefik.
- Traefik maakt gebruik van de services van Let's Encrypt om automatisch te voorzien in SSL/TLS-certificaten.
- Ook Ollama in Docker te draaien.
- Hoewel dat normaal geen goed idee (GPU-toegang via Docker is ingewikkeld) is, heeft de server vanuit school geen GPU en zou Docker in dit geval geen merkbare vertraging moeten opleveren.
- In een omgeving waar dit wel verschil zou maken (zie hoofdstuk Hardware), kan de
docker-compose-with-ollama.ymlfile vervangen worden voordocker-compose.ymlen dient Ollama direct op de host gedraaid te worden.
- Het frontend, het backend en de gebruikershandleiding beschikbaar te maken via dezelfde hostname
hhs-ai.nl. - De overdrachtshandleiding beschikbaar te maken via
handover-manual.hhs-ai.nl.
compose.yml
In onderstaand bestand zijn enkele regels uitgecomment met een #. Deze regels dienen ter debug en kunnen in de praktijk het beste gecomment blijven, tenzij er problemen zijn en het noodzakelijk is meer debuginformatie te verzamelen.
include:
- path:
- Sources/rott-backend/docker-compose-with-ollama.yml
- override.yaml
services:
traefik:
image: traefik:3.3
container_name: traefik
command:
# - --log.level=DEBUG
- --api=true
- --api.dashboard=true
- --providers.docker=true
- --providers.docker.exposedbydefault=false
# HTTP
- --entrypoints.web.address=:80
- --entrypoints.web.http.redirections.entryPoint.to=websecure
- --entrypoints.web.http.redirections.entryPoint.scheme=https
# HTTPS
- --entrypoints.websecure.address=:443
- --entrypoints.websecure.asDefault
- --entrypoints.websecure.http3
- --entrypoints.websecure.http.tls.certresolver=myresolver
# Let's Encrypt
- --certificatesresolvers.myresolver.acme.tlschallenge=true
# - --certificatesresolvers.myresolver-dev.acme.caserver=https://acme-staging-v02.api.letsencrypt.org/directory
- --certificatesresolvers.myresolver.acme.email=S.A.intHout@student.hhs.nl
- --certificatesresolvers.myresolver.acme.storage=/letsencrypt/acme.json
ports:
- 80:80
- 443:443
- 443:443/udp
volumes:
- /run/docker.sock:/var/run/docker.sock:ro
- traefik-letsencrypt:/letsencrypt
# labels:
# - traefik.enable=true
# - traefik.http.routers.dashboard.rule=Host(`traefik-debug.hhs-ai.nl`)
# - traefik.http.routers.dashboard.service=api@internal
networks:
- backend
restart: always
frontend:
container_name: h-ai-frontend
build:
context: ./Sources/rott-frontend
dockerfile: ./Dockerfile
args:
- REACT_APP_API_BASE_URL=https://hhs-ai.nl
volumes:
- ./Sources/rott-docs/User/Gebruikershandleiding.pdf:/usr/share/nginx/html/H-AI-Gebruikershandleiding.pdf
expose:
- 80
networks:
- backend
labels:
- traefik.enable=true
- traefik.http.routers.frontend.rule=Host(`hhs-ai.nl`) && !PathPrefix(`/quizzes`) && !PathPrefix(`/docs`) && !Path(`/openapi.json`)
restart: always
docs:
container_name: h-ai-handover-manual
build:
context: ./Sources/rott-docs/Handover
dockerfile: ./Dockerfile
expose:
- 8001
volumes:
- ./Sources/rott-docs/Handover:/book-src
networks:
- backend
labels:
- traefik.enable=true
- traefik.http.routers.docs.rule=Host(`handover-manual.hhs-ai.nl`)
- traefik.http.services.docs.loadbalancer.server.port=8001
restart: always
volumes:
traefik-letsencrypt:
name: traefik-letsencrypt
override.yml
services:
backend:
expose:
- 8000
ports: !override []
labels:
- traefik.enable=true
- traefik.http.routers.backend.rule=Host(`hhs-ai.nl`) && (PathPrefix(`/quizzes`) || PathPrefix(`/docs`) || Path(`/openapi.json`))
- traefik.http.services.backend.loadbalancer.server.port=8000
Hardware
Tijdens het ontwikkelen hebben we op veel verschillende hardware kunnen testen. Dit, omdat het prototype al kan draaien wanneer er 16 GB RAM is. In theorie zou daarmee bijvoorbeeld een Raspberry Pi 5 met 16 GB RAM het gehele prototype kunnen draaien. Echter blijkt de snelheid erg af te hangen van de rekenkracht die je meebrengt, en niet zozeer van extra (> 16 GB) RAM-geheugen. De genoemde Raspberry Pi zal daardoor toch afvallen.
Zo:
- Werkt het op moderne AMD/NVIDIA desktop GPU's met 16 GB VRAM (videogeheugen) het allersnelst.
- Maar kan Ollama de lagen van een LLM verdelen over CPU en GPU indien nodig.
- Werken Apple Silicon GPU's redelijk snel.
- Zijn Intel GPU's (zowel integrated als Intel Arc) nog niet ondersteund door Ollama.
- Zal Ollama automatisch de CPU gebruiken als de GPU niet geschikt is, terwijl CPU's aanzienlijk slechter performen bij AI inference.
Alle hieronder uiteengezette configuraties gaven geen fouten, maar verschilden slechts in performance:
| Type | CPU | GPU | Snelheid | Opmerkingen |
|---|---|---|---|---|
| Desktop | AMD Ryzen 9 5900X | Intel Arc A770 | ⚠️ | Intel Arc desktop GPU nog niet ondersteund door Ollama |
| Laptop | Apple M2 Pro (12 core) | Apple M2 Pro (19 core) | ⚠️ | |
| Laptop | Apple M1 | Apple M1 (7 core) | ⚠️ | |
| Laptop | Intel Core Ultra 5 | Intel Arc A770 | ❌ | Intel Arc integrated GPU nog niet ondersteund door Ollama |
| Desktop | AMD Ryzen 7 9700X | AMD Radeon 7800XT | ✅ |
Legenda:
- ✅: Goed (Genereert 20 vragen in < 1 minuut)
- ⚠️: Acceptabel (Genereert 20 vragen in 1 - 5 minuten)
- ❌: Niet geadviseerd (Werkt, maar doet er langer over)
Mogelijke softwareverbeteringen
Op een bepaald moment hebben wij de knoop doorgehakt om Ollama te gebruiken voor de LLM inference. Echter ondersteunt LangChain ook veel andere inference engines zoals llama.cpp. Omwille van tijd en daardoor beperkte scope, hebben we dit niet kunnen testen.
Llama.cpp heeft een veel grotere hardwareondersteuning, waarmee vooral veel Intel hardware ook binnen de boot valt.
Het is belangrijk aandacht te besteden aan de wijze waarop de inference engine gedraaid wordt. Draait deze in Docker? Dan kan het zo zijn dat toegang tot de GPU niet mogelijk is. De engine zal dan proberen op de CPU te draaien, met een meestal dramatisch lagere snelheid tot gevolg. Het is uitdagend om Docker zo te configureren dat er wel GPU toegang is.
Het is ons advies daarom om de inference library of tool buiten Docker (direct op de host) te draaien.
Advies
Op basis van de resultaten kunnen we een advies voor hardware uitbrengen. Er zijn verschillende opties om het project goed te kunnen draaien.
Geschikte videokaarten
Zoals gezegd wordt het beste resultaat bereikt met een videokaart met AMD- of NVIDIA-chip, aangezien deze vrijwel altijd goed ondersteund zijn. Om qua VRAM wat marge over te houden adviseren we voor minimaal 16 GB VRAM te kiezen. Dit zorgt voor een veilige marge waarmee veel middelgrote LLM's, waaronder de door ons uitgekozen, goed kunnen draaien naast dat je de videokaart nog kunt gebruiken als primaire videokaart voor beelduitvoer.
Geschikte GPU's zijn:
- AMD Radeon RX 6800 of hoger (binnen de 6000-serie)
- AMD Radeon RX 7600 XT of hoger (binnen de 7000-serie)
- NVIDIA RTX A4000 of hoger (binnen de A-serie)
- NVIDIA RTX 3090 of hoger (binnen de 3000 serie)
- NVIDIA RTX 4070 Ti of hoger (binnen de 4000-serie, maar let op >= 16 GB VRAM ⚠️)
- NVIDIA RTX 5070 Ti of hoger (binnen de 5000-serie)
In praktijktests waarbij Ollama volledig de GPU gebruikte, was er nauwelijks CPU-gebruik meetbaar. Onze conclusie daaruit is dat deze videokaarten eventueel aan een oudere machine toegevoegd kunnen worden, om deze geschikt te maken voor LLM-experimenten of zelfs voor een budget-productieserver.
Veel inference engines kunnen de verschillende lagen waar een LLM uit bestaat verdelen over de CPU en de GPU. Hierbij krijgt de GPU vaak de voorkeur. De lagen die vanwege VRAM en/of rekenkracht niet meer op de GPU kunnen, worden op de CPU uitgevoerd.
Wanneer voor ontwikkeldoeleinden een videokaart met 16 GB VRAM geen optie is, kan het prototype daardoor mogelijk nog steeds acceptabel draaien op kleinere hardware.
Apple Mac mini
Tijdens onze test bleek een Macbook Pro met Apple M2 Pro CPU/GPU erg acceptabel te werken. De nieuwere Apple M4 Pro is alweer aanzienlijk sneller en zou naar onze verwachting tegen "Goed" aan moeten presteren.
Een laptop lijkt ons geen praktische keuze voor hosting of voor prototyping door een team, maar deze processor is ook te vinden in de laatste Mac mini. Voor een beperkte meerprijs is deze beschikbaar met 4 extra GPU-cores voor een totaal van 20 GPU-cores. De prijs van deze samenstelling ligt op het moment van schrijven tegen de €2000. Dit maakt de Mac mini naar ons idee een geschikte tool voor onderzoek naar LLM's en mogelijk voor een kleine productieomgeving.
NVIDIA Project DIGITS
Naast videokaarten maakt NVIDIA ook CPU's. Begin 2025 heeft NVIDIA dan ook een eigen server aangekondigd die gebruik maakt van een eigen ontwerp CPU en GPU. Deze server is specifiek gebouwd om AI-taken te accelereren, waaronder het gebruik van LLM's. RAM-geheugen en opslag zit erbij, waarmee dit net zoals de Apple Mac mini een handige keuze kan zijn doordat alle benodigdheden reeds geintegreerd zijn. Tevens biedt de grote hoeveelheid RAM (128 GB) een kans om met grotere LLM's te experimenteren.
Op het moment van schrijven is deze server nog niet te koop, maar naar verwachting zal de prijs rond de $3000 liggen.
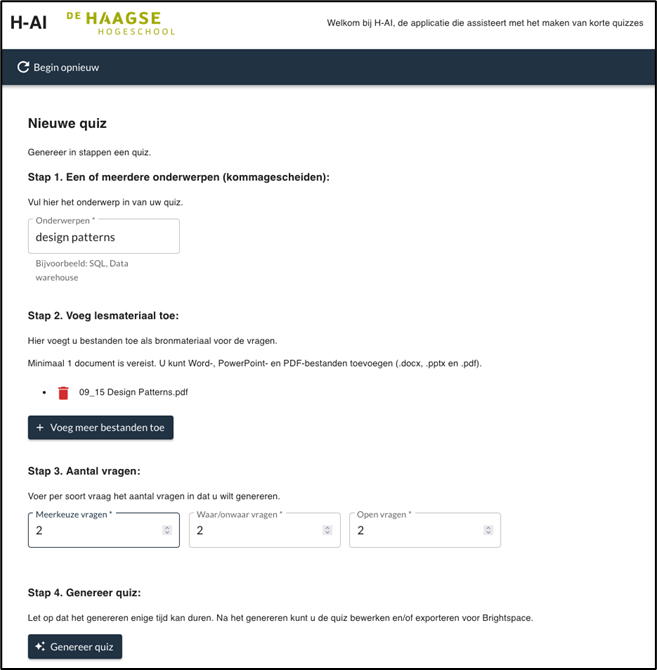
Prototype
Als het prototype draait, kun je de applicatie gebruiken. Het genereren van een quiz ziet er als volgt uit:
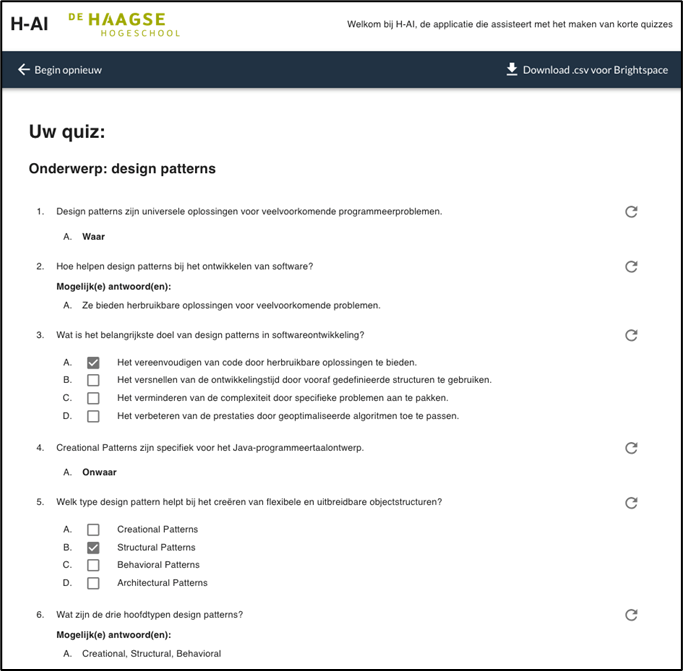
Wanneer het genereren klaar is, krijg je de resultaten te zien:
Je kunt de gegenereerde quiz exporteren naar een .csv-bestand in het juiste formaat voor Brightspace en importeren:
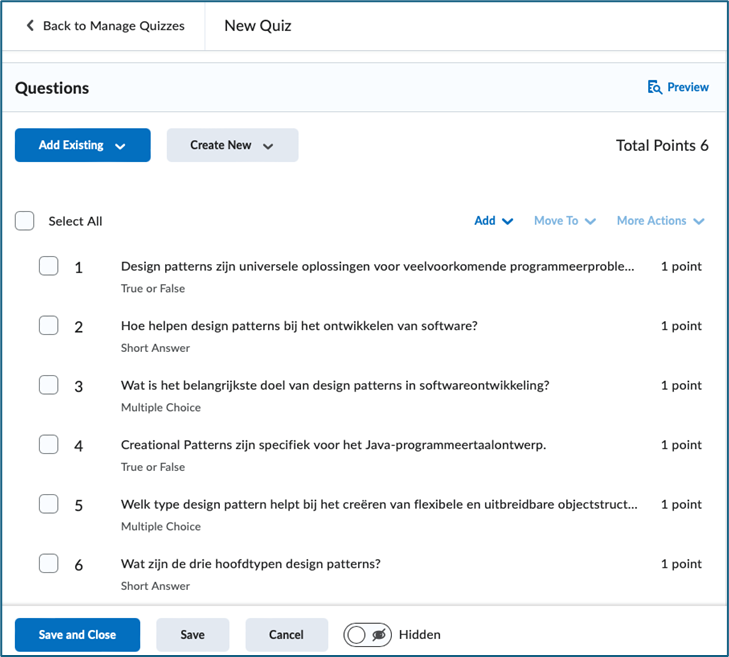
In Brightspace kun je deze quiz vervolgens previewen, zodat je hem ziet zoals de student hem zou zien:

Gebruikerstest
Om te testen in hoeverre het prototype goed werkt voor docenten (de UI simpel en zelfdocumenterend genoeg is, bruikbare vragen genereert en snel genoeg werkt) hebben we een gebruikerstest gedaan. Hiervoor hebben we 7 docenten, sommige op locatie (op school) en sommige remote laten testen met het prototype. Hierbij hebben we de gebruikers geinstrueerd en laten testen met eigen lesmateriaal en een zelfgekozen onderwerp.
De resultaten zijn uitgebreid uiteengezet in ons verantwoordingsdocument.
Resultaat
De resultaten van de gebruikerstest hebben we bij elkaar gevoegd en vereenvoudigd uiteengezet in een mindmap:
%%{init: {'theme':'default'}}%%
mindmap
root((AI Quizgenerator))
Gebruiksgemak
::icon(fa fa-user)
Eenvoudig ++
HHS huistijl ++
Niet op de hoogte van de quiz-functie in Brightspace ++
Functionaliteit
::icon(fa fa-cogs)
Verwachtingen overtroffen +
Graag afwisseling met meer inzichtvragen -
Zou 1⁄3 van de vragen zo kunnen gebruiken voor de les +/-
Nederlandse taalkwaliteit is volgende, sommige woorden werden wel letterlijk vertaald +
Gebruik van PowerPoint-, Word- en PDF-bestanden als lesmateriaal ++
Inzetbaarheid
::icon(fa fa-graduation-cap)
Oefenapplicatie voor studenten
Vaardigheden toetsen bij docenten
Andere faculteiten dan de IT-afdelingen
Innovatie
::icon(fa fa-magic)
Controle over quiz/toets-samenstelling +/-
Frontend layout overzichtelijker -
Vraaggroepering bepalen
Duidelijke eisen voor sleutelwoorden onderwerp
Multiple-choice vragen als letters i.p.v. cijfers
Vergelijking met ChatGPT, meer inzichtvragen --
Engelstalige versie +/-
Verwijderen en toevoegen van enkele nieuw gegenereerde vragen -
Afbeeldingen gebruiken bij de quizgenerator --
Validatie voor de applicatie --
Frontend validatie
Prompt voor hergenereren van quizvragen --
Incorrecte true/false antwoorden corrigeren --
Onze voorstellen voor volgende ontwikkelstappen zijn te vinden in het hoofdstuk Verdere ontwikkeling.
Oplevering
Aan het einde van het semester leveren wij een aantal zaken op. In dit hoofdstuk lichten wij deze toe en waar ze te vinden zijn.
Onderzoek
Ons onderzoek is in het kort toegelicht in deze overdrachtshandleiding. Meer informatie over het LLM-gedeelte is te vinden in onze paper. Het gehele onderzoek valt te lezen in ons verantwoordingsdocument. Deze documenten zijn ingeleverd bij onze opdrachtgever en kunnen dan ook in overleg bij de opdrachtgever ingezien en/of verkregen worden.
Designs zijn samen met losse prototype-scripts te vinden in de volgende Git-repository: https://github.com/coecs-hhs/rott-design-and-prototypes
Documentatie
De documentatie die we opleveren bestaat uit een gebruikershandleiding en deze overdrachtshandleiding, samen met Docker- en Docker Compose-bestanden om eenvoudig lokaal aan de handleiding te kunnen werken en deze te kunnen hosten.
Beiden zijn te vinden op: https://github.com/coecs-hhs/rott-docs
Programmatuur
De programmatuur die we opleveren bestaat uit het frontend en het backend, samen met Docker Compose-bestanden voor het developen en hosting.
Het frontend en backend zijn respectivelijk te vinden op:
Hosting
Om een productieomgeving te kunnen opleveren en demonstreren hebben we een domeinnaam gekocht. Deze staat op naam van projectlid Sander in 't Hout en kan eventueel (uiteraard kosteloos) overgenomen worden. Zie whois.nl voor contactgegevens of stuur (indien nog mogelijk) een bericht via Teams.
De server waar het project op het moment van schrijven op draait, is via school verkregen (de opdrachtgever kan contact leggen met de beheerder indien nodig).
De productieomgeving bestaat uit de volgende URLs:
- hhs-ai.nl: Frontend en backend
- handover-manual.hhs-ai.nl: Overdrachtshandleiding
Voor eindgebruikers is de gebruikershandleiding te vinden via een knop in het frontend.
Verdere ontwikkeling
Ondanks dat er veel gelukt is en er een werkend prototype is, is er nog genoeg te doen! Omwille van de korte ontwikkeltijd zijn er, zoals te lezen in het hoofdstuk Requirements, lastige keuzes gemaakt. Daarnaast is er feedback gekomen uit de gebruikerstest en van de opdrachtgever. In dit hoofdstuk in het kort dan ook een aantal suggesties voor verdere ontwikkeling.
Feedback uit gebruikerstest
Functioneel
- Opslaan en organiseren van cursusmaterialen en quizzen onder persoonlijke accounts.
- CRUD voor quizvragen.
- Een API voor een verder geautomatiseerde koppeling met Brightspace.
Prompting
- Niveau van quizvragen kunnen bepalen.
- Mix van kennis- en inzichtvragen (in plaats van voornamelijk kennisvragen).
- Kennis van buiten de cursusmaterialen meenemen (in plaats van enkel uit het aangeboden lesmateriaal).
- Hergenereren van vragen optimaliseren (genereert nu soms dezelfde vraag, of een vraag die er al is).
Nieuwe requirements
| ID | Actie | Meenemen | Gerealiseerd | Prioriteit |
|---|---|---|---|---|
| R1 | Vraag bewerken | ❌ | ❌ | |
| R2 | Vraag toevoegen | ✅ | ❌ | Laag |
| R3 | Vraag uithalen/verwijderen | ✅ | ❌ | Laag |
| R4 | Layout consistent maken | ✅ | ✅ | Hoog |
| R5 | Letters i.p.v. cijfers in multiple choice antwoorden | ✅ | ✅ | Hoog |
| R6 | Aantal vragen per vraagtype aangeven | ✅ | ✅ | Hoog |
| R7 | Frontend validatie | ✅ | ✅ | Hoog |
| R8 | Eisen voor onderwerpen duidelijker noteren | ✅ | ✅ | Hoog |
| R9 | Mogelijkheid om terug te gaan en vraag aanpassen zonder alle velden opnieuw in te hoeven vullen | ❌ | ❌ | |
| R10 | Cursusmaterialen en quizzen opslaan | ❌ | ❌ | |
| R11 | Feedback bij de vraag meegeven | ❌ | ❌ | |
| R12 | Vernederlanse-viseren oplossen (in de prompt) | ❌ | ❌ | |
| R13 | Prompt meegeven voor het hergenereren van vragen | ❌ | ❌ | |
| R14 | Verhouding kennis- en inzichtvragen | ❌ | ❌ | |
| R15 | Quizvragen over het onderwerp maar niet uit cursusmaterialen | ❌ | ❌ | |
| R16 | True/false als stelling, niet als vraag | ✅ | ✅ | Laag |
| R17 | Incorrecte true-false antwoorden (true=false, false=true) | ✅ | ✅ | Laag |
| R18 | Verhouding waar/onwaar in true-false-vragen | ✅ | ✅ | Laag |
| R19 | Hergenereren optimaliseren | ✅ | ❌ | Laag |
| R20 | Vraagtypen mixen in quiz, niet achter elkaar | ✅ | ✅ | Hoog |
| R21 | Antwoorden in multiple choice vragen mixen (om steeds dezelfde antwoordkeuzes te voorkomen) | ✅ | ❌ | Laag |
| R22 | Licenties verwerken in applicatie (beide modellen) | ✅ | ❌ | Laag |
LLM
De AI-ontwikkelingen gaan hard. De huidige LLM's zijn transformer modellen. Echter zijn er al experimenten geweest met andere typen AI-modellen.
Ook komen er nog steeds nieuwe modellen uit die op dezelfde technologie zijn gebaseerd, maar bijvoorbeeld kunnen redeneren. Het kan daardoor interessant zijn de laatste ontwikkelingen in de gaten te houden en na te gaan of een nieuwer model of een nieuwe techniek wellicht betere resultaten geeft.
Security
Het prototype is voornamelijk gebouwd ter ondersteuning van het onderzoek. Omdat we voornamelijk gefocust hebben op het AI-gedeelte van het onderzoek, zijn meerdere technische aspecten van de applicatie onderbelicht gebleven.
Er is bijvoorbeeld wel HTTPS gerealiseerd (zie hoofdstuk Hosting), maar er is bijvoorbeeld geen aandacht geweest voor andere security aspecten. Voor een veilige productieomgeving zouden wij dan ook adviseren bijvoorbeeld naar bronnen zoals OWASP te kijken.